Abstract
Motivation: The accumulation of high-throughput data in public repositories creates a pressing need for integrative analysis of multiple datasets from independent experiments. However, study heterogeneity, study bias, outliers and the lack of power of available methods present real challenge in integrating genomic data. One practical drawback of many P-value-based meta-analysis methods, including Fisher’s, Stouffer’s, minP and maxP, is that they are sensitive to outliers. Another drawback is that, because they perform just one statistical test for each individual experiment, they may not fully exploit the potentially large number of samples within each study.
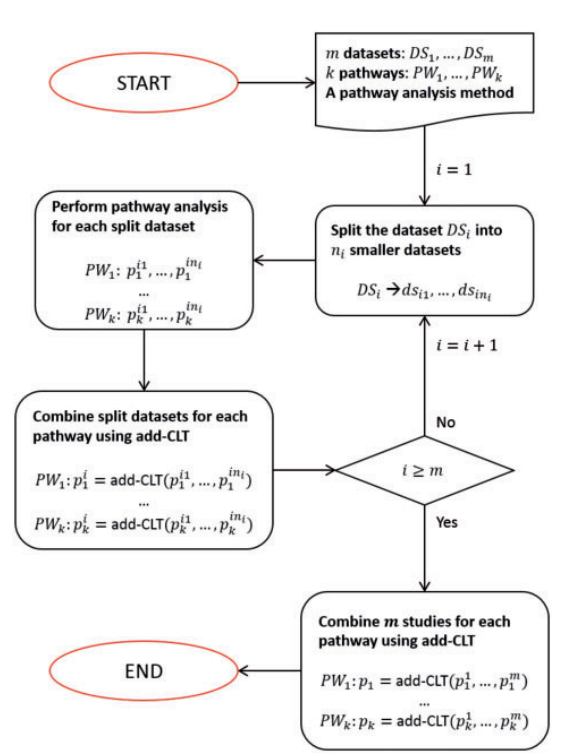
Results: We propose a novel bi-level meta-analysis approach that employs the additive method and the Central Limit Theorem within each individual experiment and also across multiple experiments. We prove that the bi-level framework is robust against bias, less sensitive to outliers than other methods, and more sensitive to small changes in signal. For comparative analysis, we demonstrate that the intra-experiment analysis has more power than the equivalent statistical test performed on a single large experiment. For pathway analysis, we compare the proposed framework versus classical meta-analysis approaches (Fisher’s, Stouffer’s and the additive method) as well as against a dedicated pathway meta-analysis package (MetaPath), using 1252 samples from 21 datasets related to three human diseases, acute myeloid leukemia (9 datasets), type II diabetes (5 datasets) and Alzheimer’s disease (7 datasets). Our framework outperforms its competitors to correctly identify pathways relevant to the phenotypes. The framework is sufficiently general to be applied to any type of statistical meta-analysis.
This package provides a bi-level meta-analysis (BLMA) framework that can be applied in a wide range of applications: functional analysis, pathway analysis, differential expression analysis,and general hypothesis testing. The framework is able to integrate multiple studies to gain morestatistical power, and can be used in conjunction with any statistical hypothesis testing method.It exploits not only the vast number of studies performed in independent laboratories, but also makes better use of the available number of samples within individual studies.