Meta-analysis is the statistical procedure for combining data from multiple studies. When the treatment effect (or effect size) is consistent from one study to the next, meta-analysis can be used to identify this common effect. When the effect varies from one study to the next, meta-analysis may be used to identify the reason for the variation. It is a set of techniques used to merge the results of a number of different reports into one report to create a single, more precise estimate of an effect. The aims of meta-analysis are to increase statistical power; to deal with controversy when individual studies disagree; to improve estimates of the size of the effect, and to answer new questions not previously posed in component studies.
The accumulation of high-throughput data in public repositories creates a pressing need for integrative analysis of multiple datasets from independent experiments. However, study heterogeneity, study bias, outliers and the lack of power of available methods present real challenge in integrating genomic data. One practical drawback of many P-value-based meta-analysis methods, including Fisher’s, Stouffer’s, minP and maxP, is that they are sensitive to outliers. Another drawback is that, because they perform just one statistical test for each individual experiment, they may not fully exploit the potentially large number of samples within each study.
TOMAS, a novel meta-analysis framework that transforms the challenging meta-analysis problem into a set of standard analysis problems that can be solved efficiently. This framework utilizes techniques based on both p-values and effect sizes to identify differentially expressed genes and their expression change on a genome-scale. The paper can be viewed here.
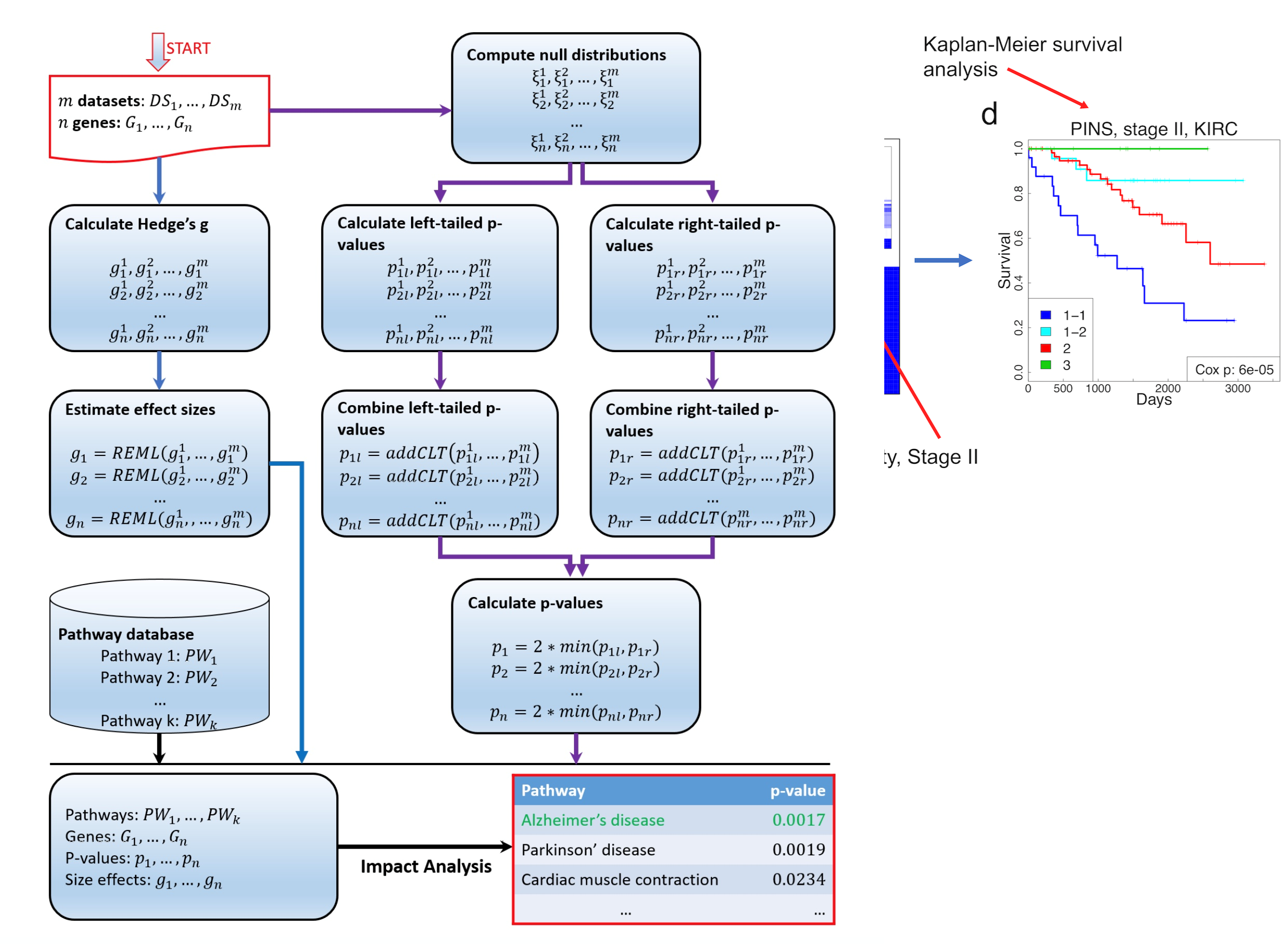
DANUBE is a novel and unbiased approach to combine statistics computed from individual studies. Our framework uses control samples to construct empirical null distributions, from which empirical pvalues of individual studies are calculated and combined using either a Central Limit Theorem approach or the additive method. We assess the performance of DANUBE using four different pathway analysis methods. DANUBE is compared with five metaanalysis approaches, as well as with a pathway analysis approach that employs multiple datasets (MetaPath). The 25 approaches have been tested on 16 different datasets related to two human diseases, Alzheimer’s disease (7 datasets) and acute myeloid leukemia (9 datasets). We demonstrate that DANUBE overcomes bias in order to consistently identify relevant pathways. We also show how the framework improves results in more general cases, compared to classical meta-analysis performed with common experiment-level statistical tests such as Wilcoxon and t-test. The paper can be viewed here.
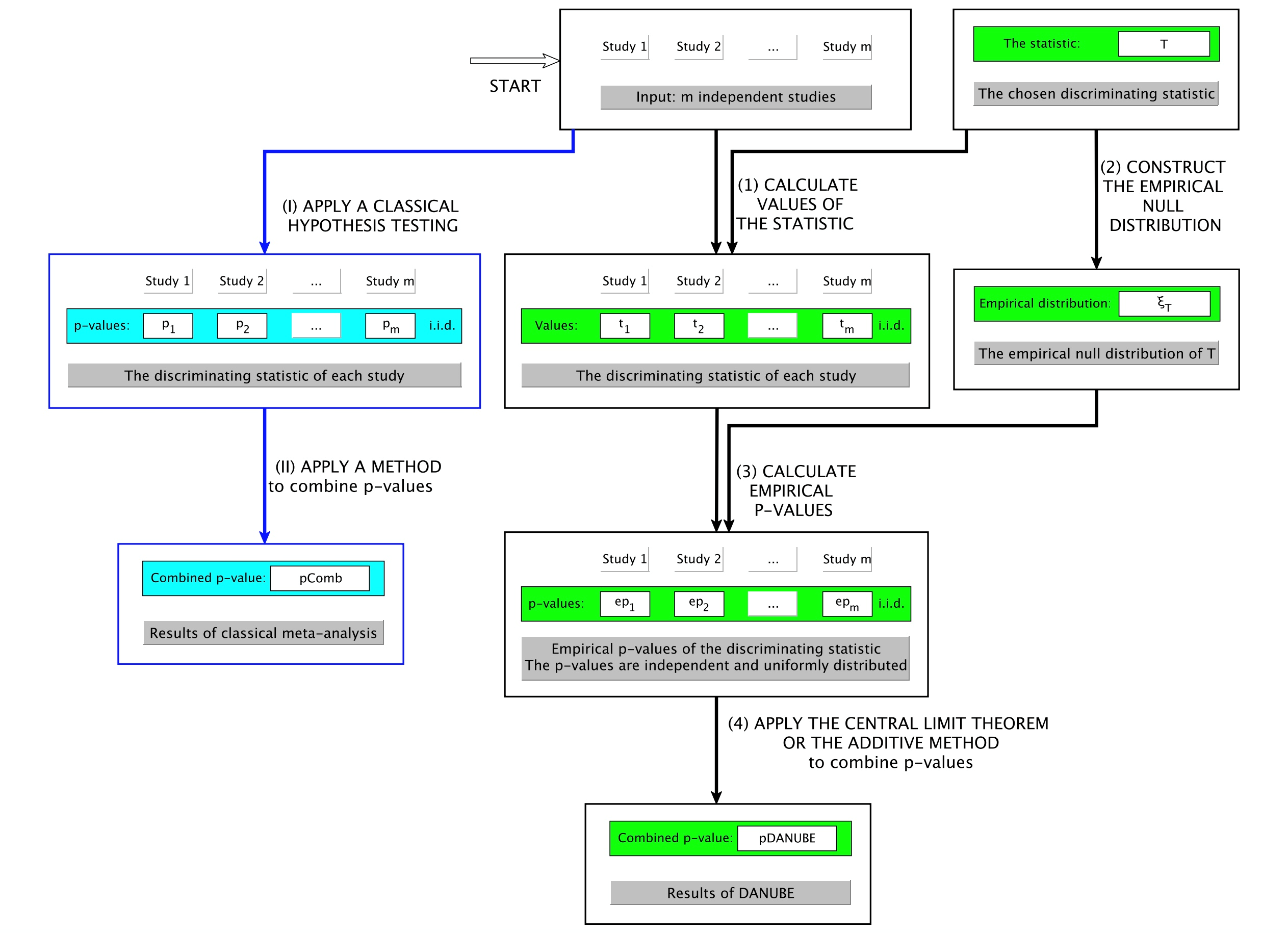
BLMA is an approach that employs the additive method and the Central Limit Theorem within each individual experiment and also across multiple experiments. We prove that the bi-level framework is robust against bias, less sensitive to outliers than other methods, and more sensitive to small changes in signal. For comparative analysis, we demonstrate that the intra-experiment analysis has more power than the equivalent statistical test performed on a single large experiment. For pathway analysis, we compare the proposed framework versus classical meta-analysis approaches (Fisher’s, Stouffer’s and the additive method) as well as against a dedicated pathway meta-analysis package (MetaPath), using 1252 samples from 21 datasets related to three human diseases, acute myeloid leukemia (9 datasets), type II diabetes (5 datasets) and Alzheimer�s disease (7 datasets). Our framework outperforms its competitors to correctly identify pathways relevant to the phenotypes. The framework is sufficiently general to be applied to any type of statistical meta-analysis.
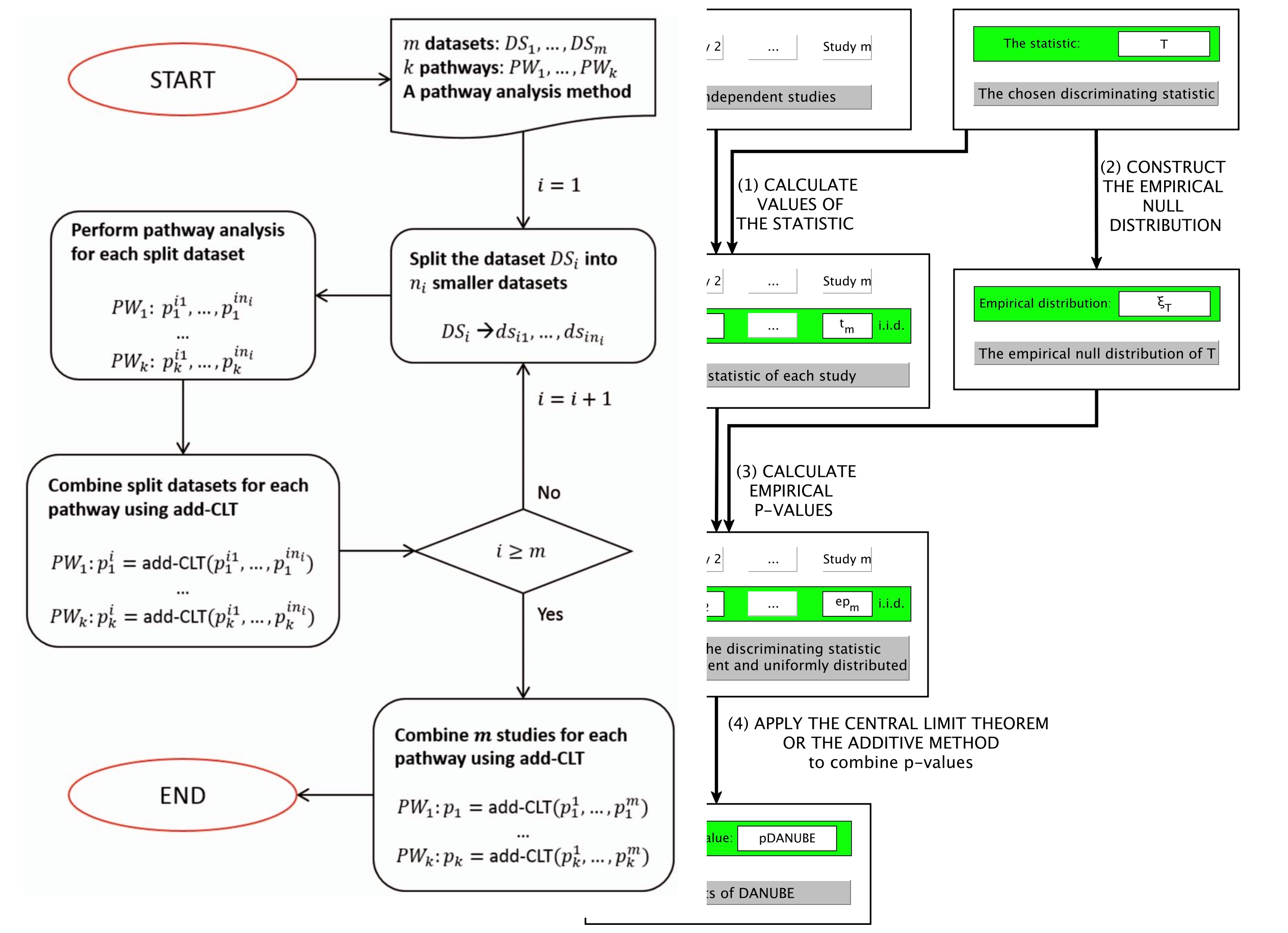
Here we propose a P-value-based meta-analysis framework which addresses the mentioned shortcomings and thus provides more reliable results. As we will demonstrate, the proposed method is not sensitive to outliers. To gain power from a large number of samples within each experiment, the proposed meta-analysis integrates multiple independent studies on two levels: an intra-experiment analysis, and an inter-experiment analysis. First, for each individual experiment, the intra-experiment analysis splits the dataset into smaller datasets, performs a statistical test on each of the newly created small datasets, then combines the P-values. Next, the inter-experiment analysis combines those processed P-values, from each of the individual experiments. We demonstrate the power of our bi-level meta-analysis in the context of pathway analysis. The paper can be viewed here and the package can be downloaded from Bioconductor.